
在线股票配资开户Position
你的位置:安全股票配资门户_在线股票配资开户_网上股票配资平台 > 在线股票配资开户 > 股票专业配资炒股 苹果牛津发现蒸馏Scaling Law!必须满足两个条件,蒸馏才有优势
发布日期:2025-02-18 15:23 点击次数:89

编辑:KingHZ 英智股票专业配资炒股
【新智元导读】苹果和牛津的研究人员提出了蒸馏扩展定律。通过一系列实验,深入剖析了蒸馏与监督学习的优劣,以及模型表现与计算资源的关系,探索模型优化的新路径。
众所周知,知识蒸馏(Distillation)可以有效压缩模型并转移知识。
此前,o3 mini被曝大量使用中文推理时,网友曾调侃OpenAI是不是「蒸馏」了DeepSeek-R1的数据
在2015年的「Distilling the Knowledge in a Neural Network」一文中,Hinton和Jeff Dean等人便提出了这种方法。(但被NeurIPS拒稿)

论文链接:https://arxiv.org/abs/1503.02531
这篇经典的工作引起了苹果公司的Dan Busbridge的思考:
如果想要一个小而高效的模型,到底是从一个更强的模型蒸馏一下,还是从头训练一个全新的模型?
他表示新研究证明蒸馏确实不简单。

最近,Dan Busbridge联合苹果和牛津的合作者提出了「蒸馏扩展定律」。
即,学生模型的性能取决于两部分:教师模型的性能和学生模仿教师模型的能力。而后者遵循所谓的「Scaling Law」。
研究结果表明,当有充足的数据或计算资源时,蒸馏也不一定产生比监督学习更好的效果。
仅当满足以下两个条件时,蒸馏才比监督学习更具优势:
1. 用于蒸馏的总计算量或token数量不超过与学生规模相关的阈值。
2. 已经存在教师模型,或者要训练的教师模型具有除单次蒸馏之外的用途。

论文链接:https://arxiv.org/abs/2502.08606
具体而言,学生模型的损失L_S取决于自身的参数规模N_S、蒸馏token数量D_S以及教师模型的损失L_T,如下:
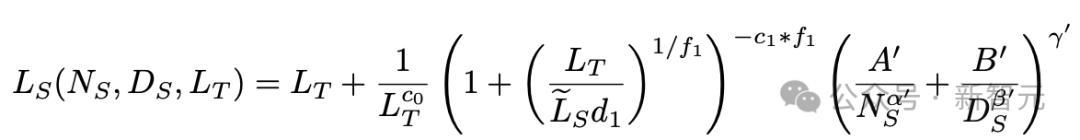
下文会解释公式中各参数的具体的含义。
研究动机
如何在有限的计算资源下,提高LLM的性能,是一个亟待解决的问题。
蒸馏是一种有效的模型压缩和知识转移方法。基本思想是通过学习教师模型的输出分布,帮助学生模型学习和优化。
研究者深入研究了蒸馏过程中的一些关键问题,比如下列问题:
如何根据计算预算和资源分配来优化蒸馏效果?
如何确定最佳的教师模型和学生模型大小?
基于弱学生(L_S>2.3)和教师损失L_T,研究人员拟合了蒸馏Scaling Law。
如图所示,学生能够超越老师。其中,实线表示在给定学生配置下,对未见过的教师进行预测模型行为(插值);而虚线则表示在未见过的教师以及强学生区域(L_S≤2.3)外进行的预测模型行为。
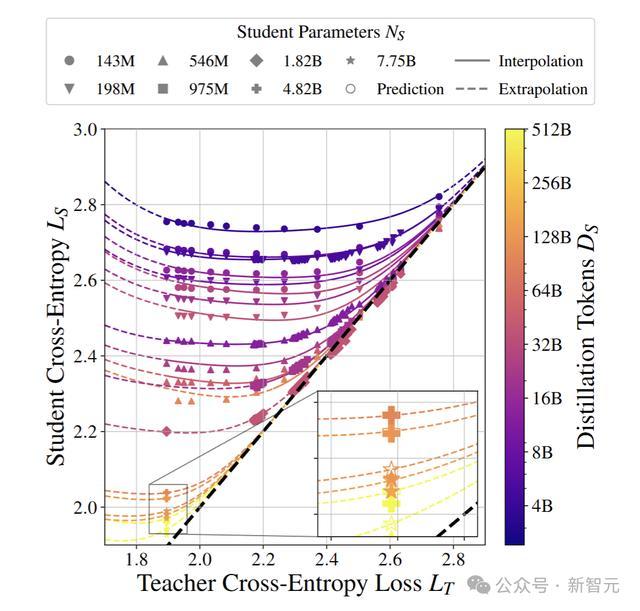
蒸馏Scaling Law的外推
蒸馏扩展定律
研究者进行了一系列的实验,主要目的是探究蒸馏过程中模型性能与计算资源之间的关系,以及如何通过优化计算资源的分配来提高蒸馏的效率和性能。
只有特定的数据组合,才能可靠地确定扩展定律系数。
研究者用三个实验来为蒸馏扩展定律拟合产生数据。下表是文中符号的含义。

实验中选择了多种不同规模的LLM作为教师模型和学生模型,包括GPT、BERT等,模型参数从143M到12.6B,训练数据最多达512B token,覆盖了不同的应用场景和需求。
使用了大量的文本数据作为蒸馏数据,包括新闻文章、小说、论文等。实验中设置了不同的计算资源限制,包括计算时间、计算成本等。
固定M教师/学生IsoFLOP实验
研究者预测在固定教师模型的情况下,学生模型参数N_S和训练token数量D_S间会呈现幂律关系。
首先固定教师模型的规模和训练数据,然后通过改变学生模型的规模和训练数据,来研究学生模型的性能如何随着教师模型和训练数据的变化而变化。
将教师模型固定在975M(图2左)和7.75B(图2右)的规模,在不同算力(不同颜色圆点)下,学生模型的性能和规模的关系并不简单:
1. 在算力较大的情况下,参数规模越大,学生模型的损失函数越小,也就是性能越好,而且教师模型规模越大,这种趋势越明显。
2. 在算力较小的情况下,模型性能会随着模型规模先提高,后减弱。
3. 在学生和教师模型规模确定的情况下,算力越多,学生模型的确表现越好。
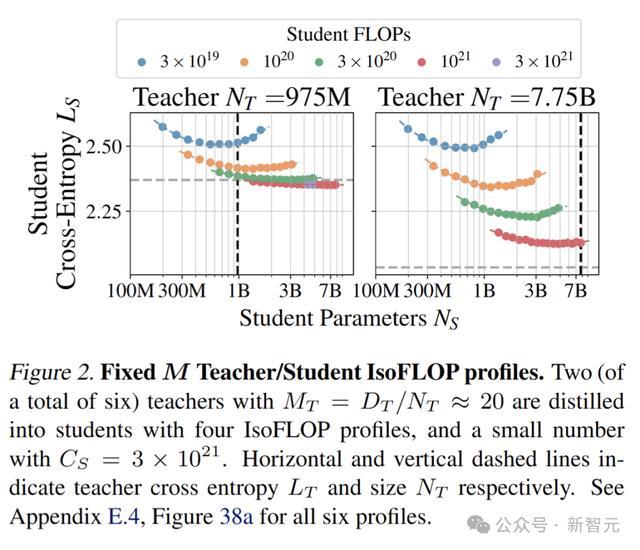
也就是说在某些特殊情况下,学生模型能够优于教师模型,表现出泛化能力。
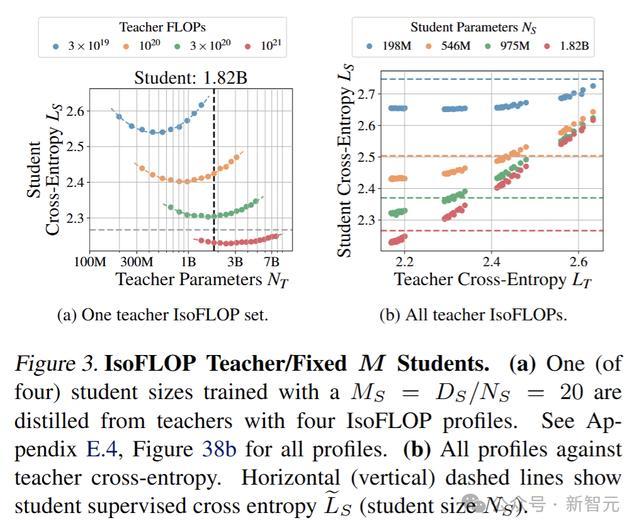
IsoFLOP教师/固定M学生实验
固定学生模型的规模和训练数据,然后通过改变教师模型的规模和训练数据,来研究学生模型的性能如何变化。
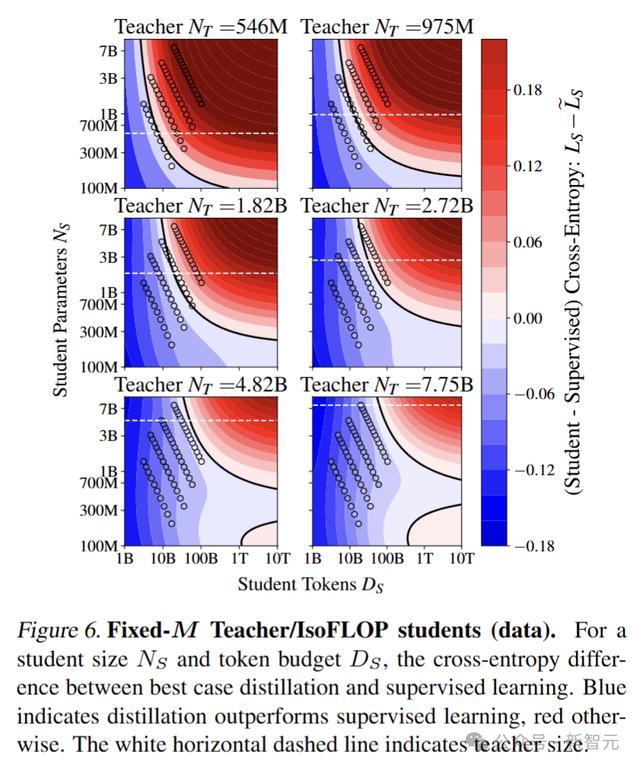
设定学生(N_S,D_S)为固定值,N_T和D_T在计算约束下变化。进行蒸馏实验,将四个Chinchilla最优(M_S=D_S/N_S≈20)的学生模型从4种配置训练的教师模型中蒸馏出来。得到的学生交叉熵如图所示。
固定M教师/固定M学生实验
固定教师模型和学生模型的M值,然后通过改变实验条件,来研究学生模型的性能如何变化。
M值指token数与模型参数总数量的比值,已有研究最佳值为20。
训练固定M的教师模型与固定M的学生模型的组合,其中包含10个教师模型(M_T≈20)和5种规模的学生模型.
每个学生模型至少对应4种M_S选择。其中两个学生模型的交叉熵如图所示。
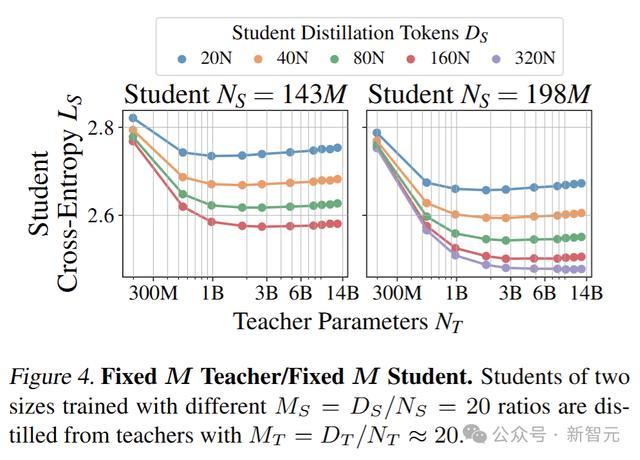
研究者观察到了能力差距(capacity gap)现象,即提升教师模型的性能并不总是能提高学生模型的性能,甚至最终可能导致学生模型性能下降。
数学函数
研究确定了Scaling Law明确的函数形式。
研究人员认为蒸馏扩展法则应当具备以下特性:
1. 无限能力的学生模型应该能够模仿任何教师模型:
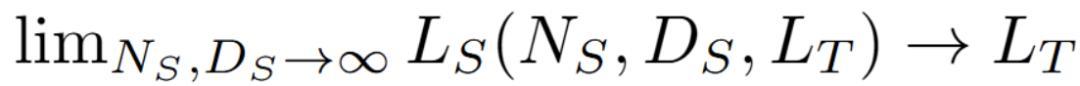
2. 一个随机教师模型产生的学生模型性能是随机的,且与学生模型的能力无关:
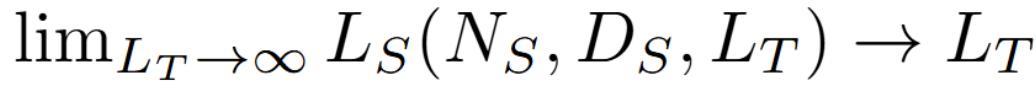
3. 存在能力差距:教师模型过于强大最终会降低学生模型的性能。
基于实验结果,研究人员建立了蒸馏扩展定律的数学模型,用以下公式来表示:
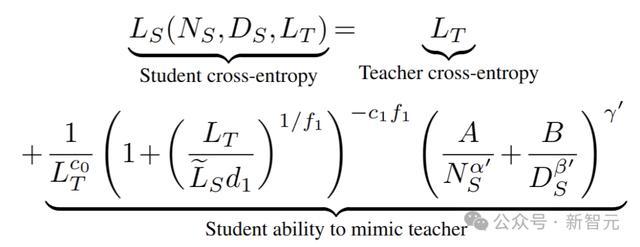
其中L_S表示学生模型的交叉熵,L_T表示教师模型的交叉熵,N_S表示学生模型的参数数量,D_S表示蒸馏数据量,
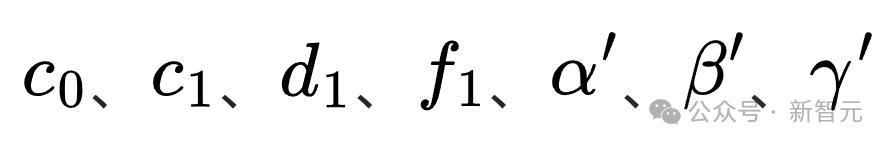
是模型的参数,需要通过数据来拟合。
这个数学模型可以用来描述蒸馏过程中学生模型的交叉熵与教师模型的交叉熵、学生模型的参数数量、蒸馏数据量以及计算资源等因素之间的关系。
通过对这个数学模型的分析和优化,可以找到最佳的计算资源分配方案,从而提高蒸馏过程的效率和性能。对于固定的模型大小,在充足数据的情况下,蒸馏与监督学习效果是一致的。
拟合Scaling Law
新研究使用所有数据来拟合蒸馏缩放规律,即下列数学公式:
拟合结果的缩放系数,参阅下表。
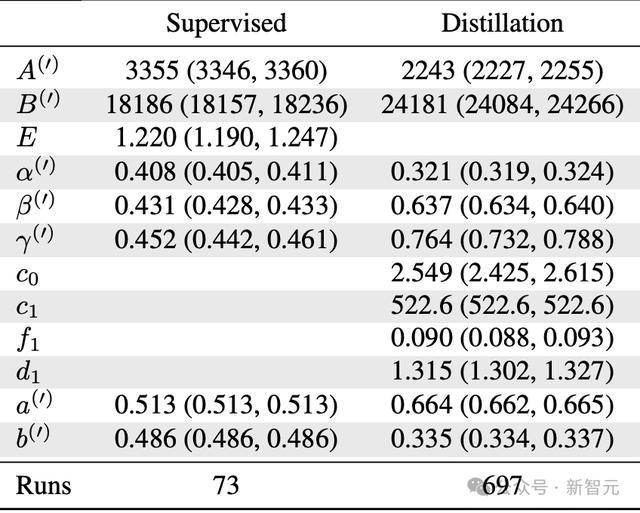
采用自助法(4096次重采样)估计的缩放规律参数,置信区间为90%
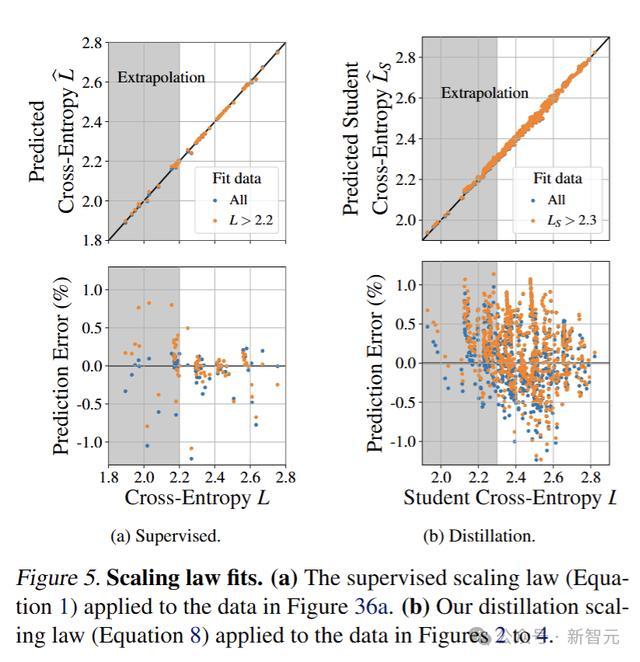
监督和蒸馏缩放规律能够在相对预测误差小于1%的水平上拟合观测结果,包括从弱模型外推到强模型的情况(见图5b)。
蒸馏扩展定律的应用场景
通常,蒸馏预训练中的资源包括计算预算或包含一定数量token的数据集。
为了解蒸馏在何时有益,探讨在最佳情况下,蒸馏与监督学习相比的表现。
在有足够的学生模型计算预算或token的情况下,监督学习总是优于蒸馏。对于适度的token预算,蒸馏是有利的,然而,当有大量token可用时,监督学习优于蒸馏。
较大的教师模型可能提供更好的学习信号(更低的交叉熵),但使用起来也会更昂贵。
对于固定的数据预算,随着学生大小的增加,教师交叉熵应按幂律减小。不同蒸馏token预算下的学生交叉熵如图所示。
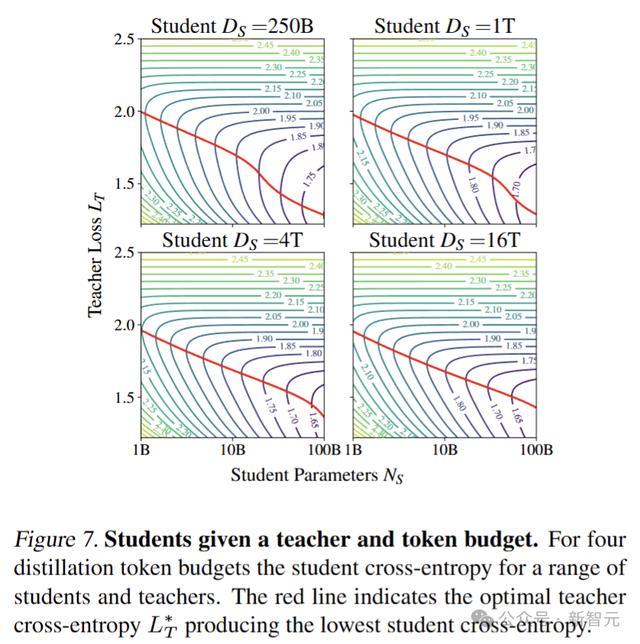
最佳教师损失L_T*(红线)随着学生大小N_S的幂律减小,直到L_S与L_T*匹配,此时L_T*出现拐点,导致教师损失的减小随着N_S的增加而加剧。
这验证了「最佳教师规模几乎始终与学生规模呈线性比例关系。」
在足够的计算预算下,监督学习总是与最佳蒸馏匹配,并且随着学生规模的增长,有利于监督学习的交叉点也会增加。
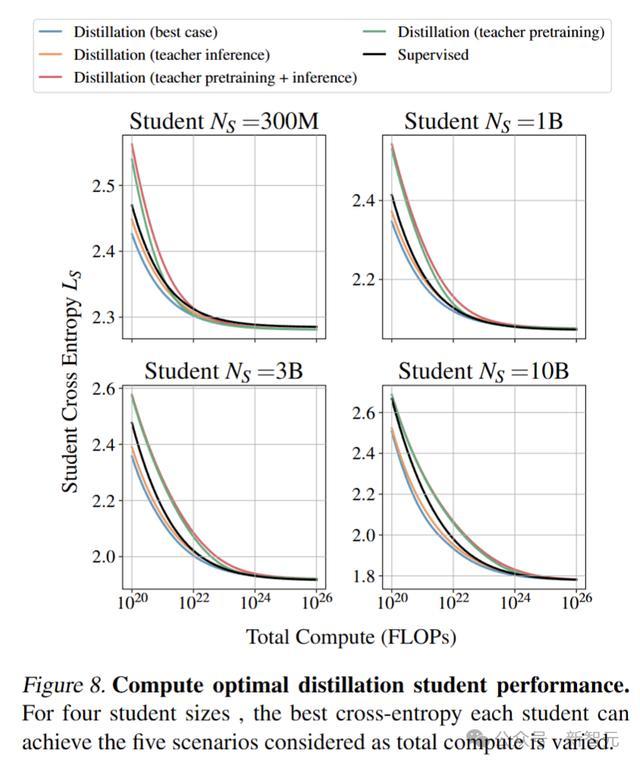
图中可以看到,监督学习在某些计算预算下总是与最佳蒸馏设置一致。
较小的模型更可能从监督预训练中受益,而较大的模型更可能从蒸馏中受益。
当教师训练包含在计算中时,最佳学生交叉熵总是高于监督设置。这意味着如果唯一目标是产生目标大小的最佳模型,并且没有教师可用,应该选择监督学习,而不是训练教师模型然后进行蒸馏。
相反,如果目的是蒸馏出一系列模型,或使用教师作为服务模型,那么蒸馏可能比监督学习在计算上更有益。
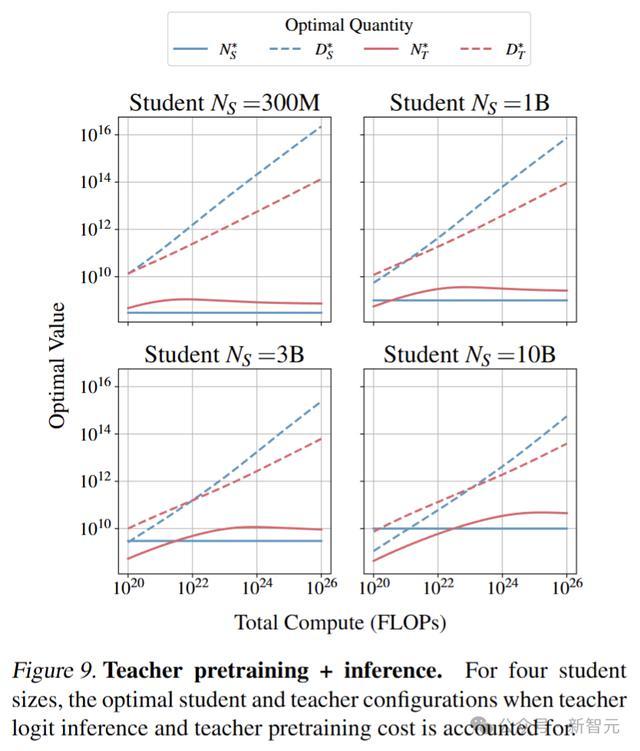
学生和教师模型的token按幂律缩放,学生token的增长速度更快。最佳教师模型规模最初增加,直到略大于学生,之后趋于稳定。
这是因为使用大型教师模型进行推理成本很高,并且随着学生token数量的增加,过拟合教师模型更有效。
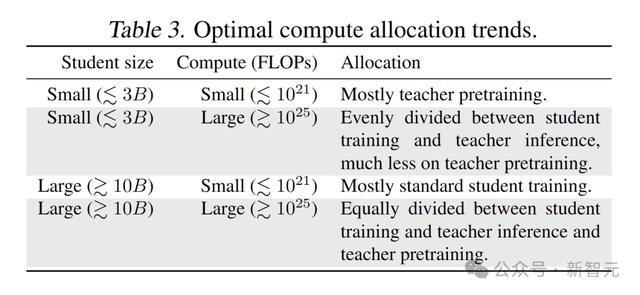
研究通过对不同规模和复杂度的模型进行实验,验证了蒸馏扩展定律的有效性。
实验结果表明股票专业配资炒股,蒸馏扩展定律能够较好地描述蒸馏模型性能与计算预算、教师模型和学生模型之间的关系,为LLM的训练提供了重要的理论支持。
Powered by 安全股票配资门户_在线股票配资开户_网上股票配资平台 @2013-2022 RSS地图 HTML地图